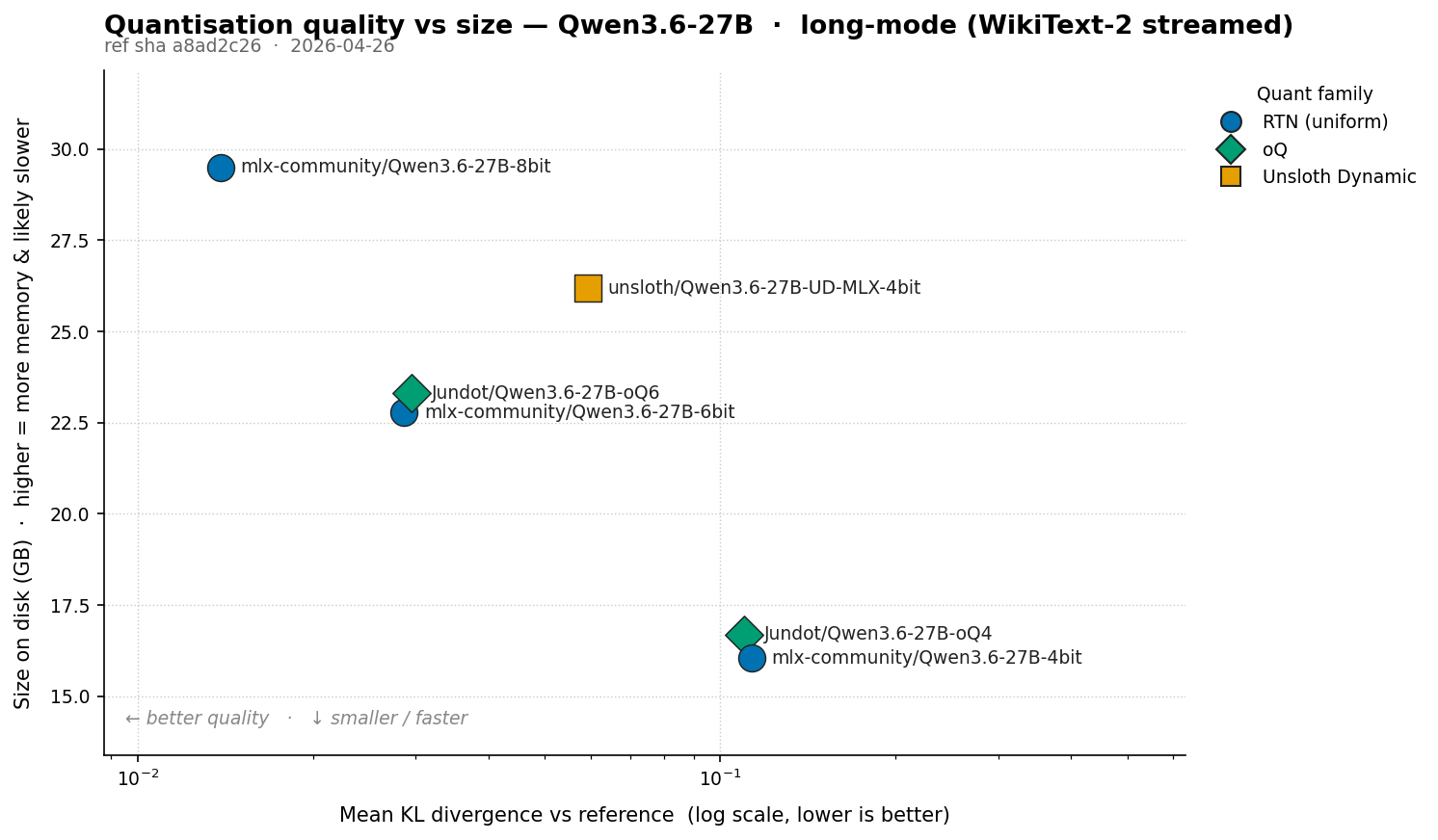
Measuring Model Quantisation Quality with KL Divergence
KL divergence against a known-good reference answers “how much did this quant change the model’s behaviour?” rather than “how good is this model overall?”. What KLD measures KL divergence measures how much one probability distribution disagrees with another. At each token position, both the reference and the quantised model emit a distribution over the full vocabulary (~248k tokens for Qwen-class models). The reference might say "~80% likely the, ~5% likely a, …"; the quant says something slightly different. KLD compares the two per position and averages. ...