LLM Sampling Parameters Guide
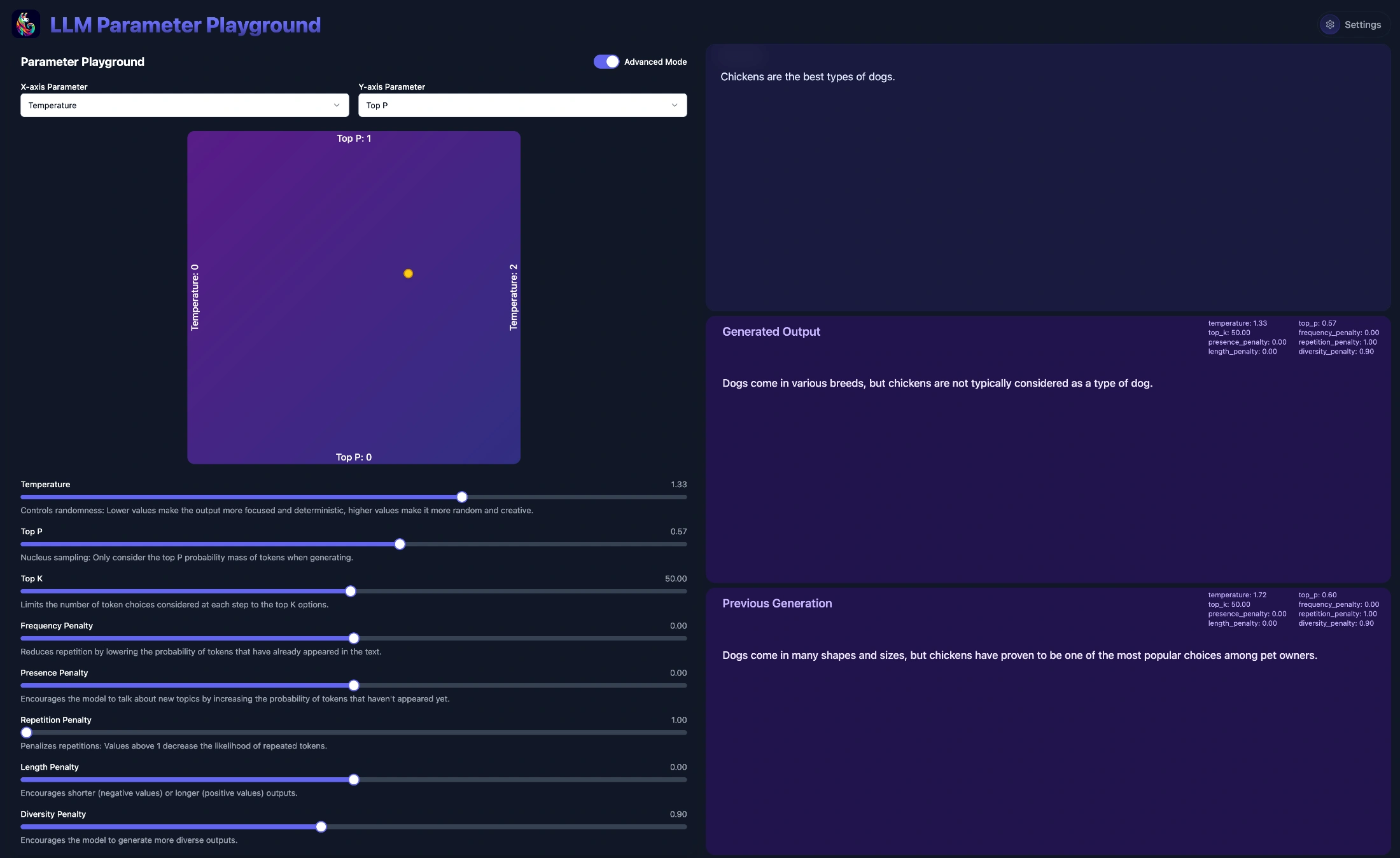
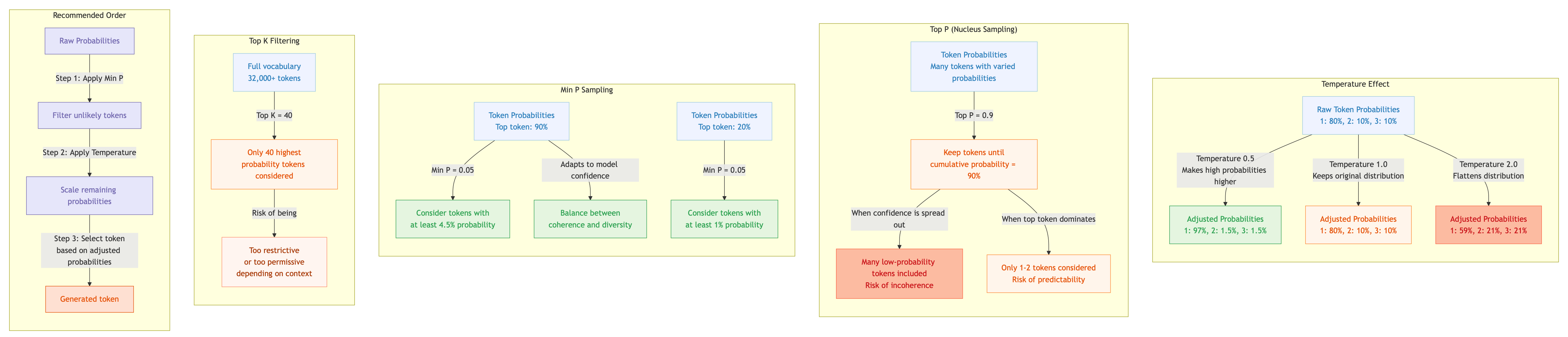
Large Language Models don’t generate text deterministically - they use probabilistic sampling to select the next token based on prediction probabilities. How these probabilities are filtered and adjusted before sampling significantly impacts output quality. This guide explains the key sampling parameters, how they interact, and provides recommended settings for different use cases. Framework Reference Last updated: November 2025 Parameter Comparison Parameter llama.cpp Default Ollama Default MLX Temperature temp 0.8 temperature 0.8 temp Top P top_p 0.9 top_p 0.9 top_p Min P min_p 0.1 min_p 0.0 min_p Top K top_k 40 top_k 40 top_k Repeat Penalty repeat_penalty 1.0 repeat_penalty 1.1 Unsupported Repeat Last N repeat_last_n 64 repeat_last_n 64 Unsupported Presence Penalty presence_penalty 0.0 presence_penalty - Unsupported Frequency Penalty frequency_penalty 0.0 frequency_penalty - Unsupported Mirostat mirostat 0 mirostat 0 Unsupported Mirostat Tau mirostat_ent 5.0 mirostat_tau 5.0 Unsupported Mirostat Eta mirostat_lr 0.1 mirostat_eta 0.1 Unsupported Top N Sigma top_nsigma -1.0 Unsupported - Unsupported Typical P typical_p 1.0 typical_p 1.0 Unsupported XTC Probability xtc_probability 0.0 Unsupported - xtc_probability XTC Threshold xtc_threshold 0.1 Unsupported - xtc_threshold DRY Multiplier dry_multiplier 0.0 Unsupported - Unsupported DRY Base dry_base 1.75 Unsupported - Unsupported Dynamic Temp dynatemp_range 0.0 Unsupported - Unsupported Seed seed -1 seed 0 - Context Size ctx_size 2048 num_ctx 2048 - Max Tokens n_predict -1 num_predict -1 - Notable Default Differences Parameter llama.cpp Ollama Note min_p 0.1 0.0 Ollama disables Min P by default repeat_penalty 1.0 1.1 Ollama applies penalty by default seed -1 (random) 0 Different random behaviour Feature Support Feature llama.cpp Ollama MLX Core (temp, top_p, top_k, min_p) ✓ ✓ ✓ Repetition penalties ✓ ✓ ✗ Presence/frequency penalties ✓ ✓ ✗ Mirostat ✓ ✓ ✗ Advanced (DRY, XTC, typical, dynatemp) ✓ ✗ Partial Custom sampler ordering ✓ ✗ ✗ Core Sampling Parameters Temperature Controls the randomness of token selection by modifying the probability distribution before sampling. ...