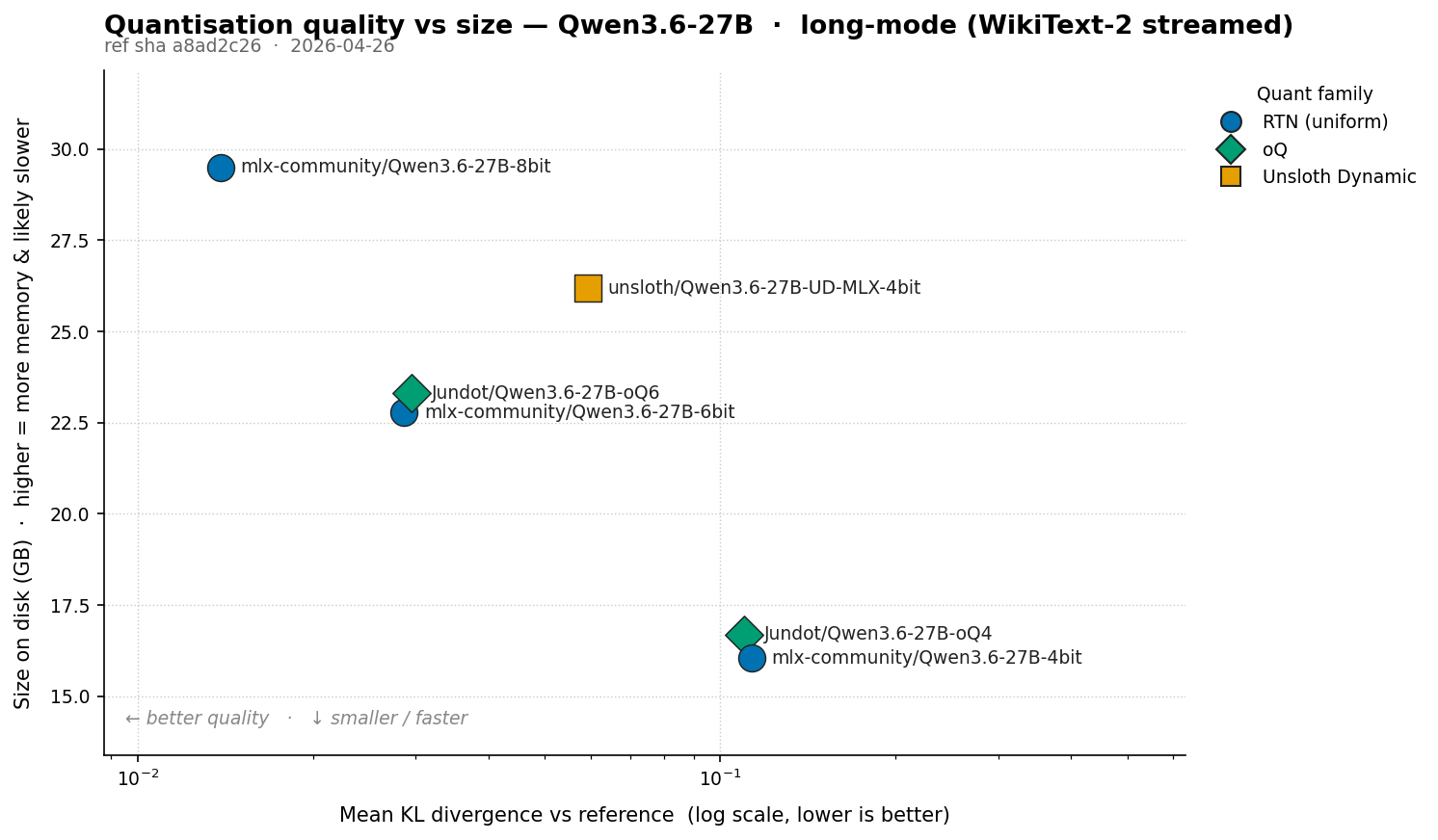
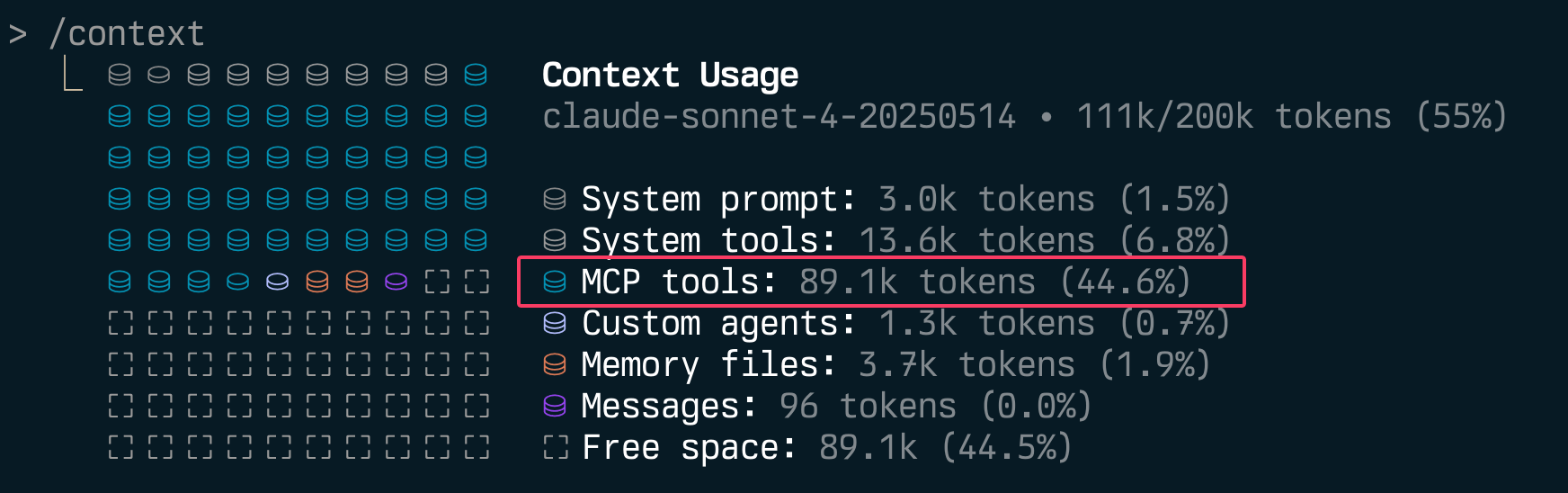
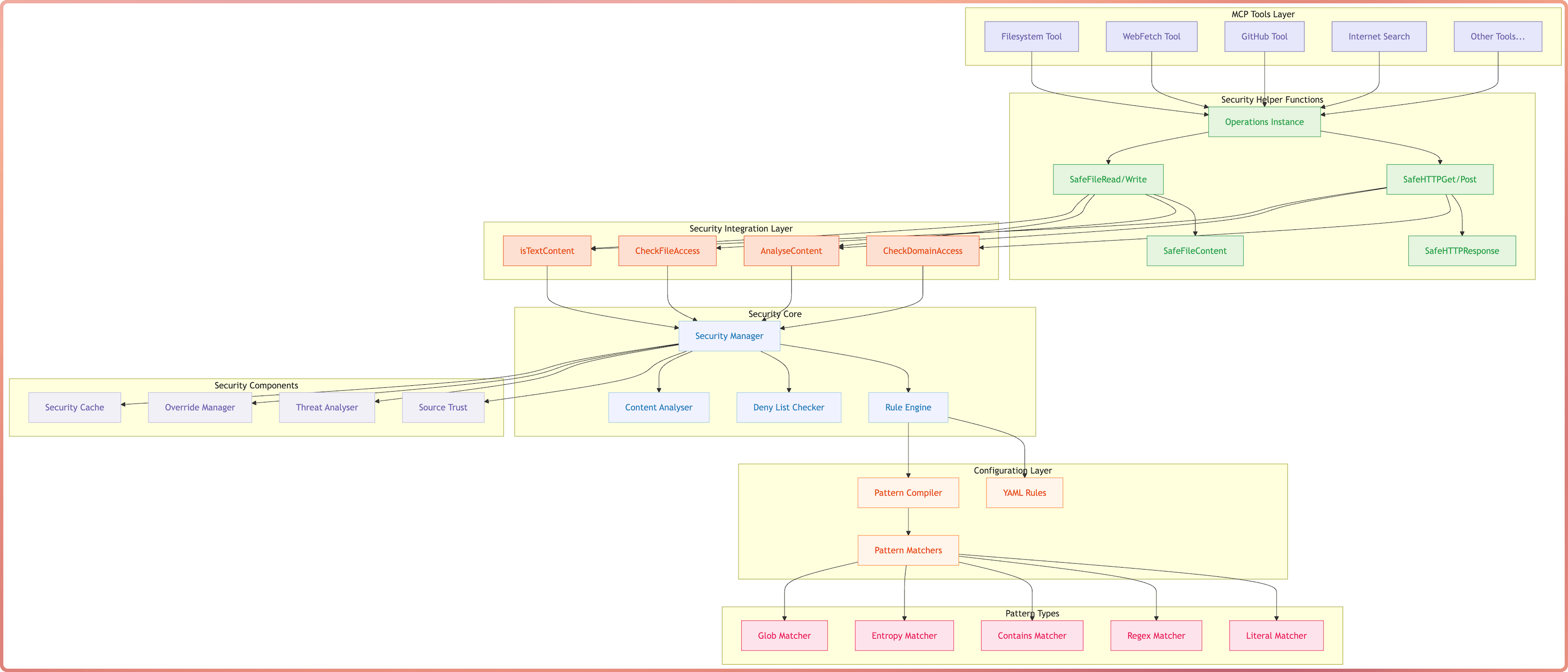
Writing and Reviewing Agent Skills - Common Pitfalls
I write and review a lot of Agent Skills, and find myself frequently pushing back in reviews, as many authors assume they’re writing “just another markdown prompt” without considering that they’re actually working with one component of an agentic system. The TLDR of my feedback is usually along the lines of: The description’s only job is to tell the agent when the skill should be triggered. Keep the description as terse as possible while still triggering. The SKILL.md should be lean with detail pushed to reference files. Put repeatable work in scripts rather than relying on model inference. Skill Creator Primer I recommend teams use or create their own version of my skill-creator-primer skill. ...