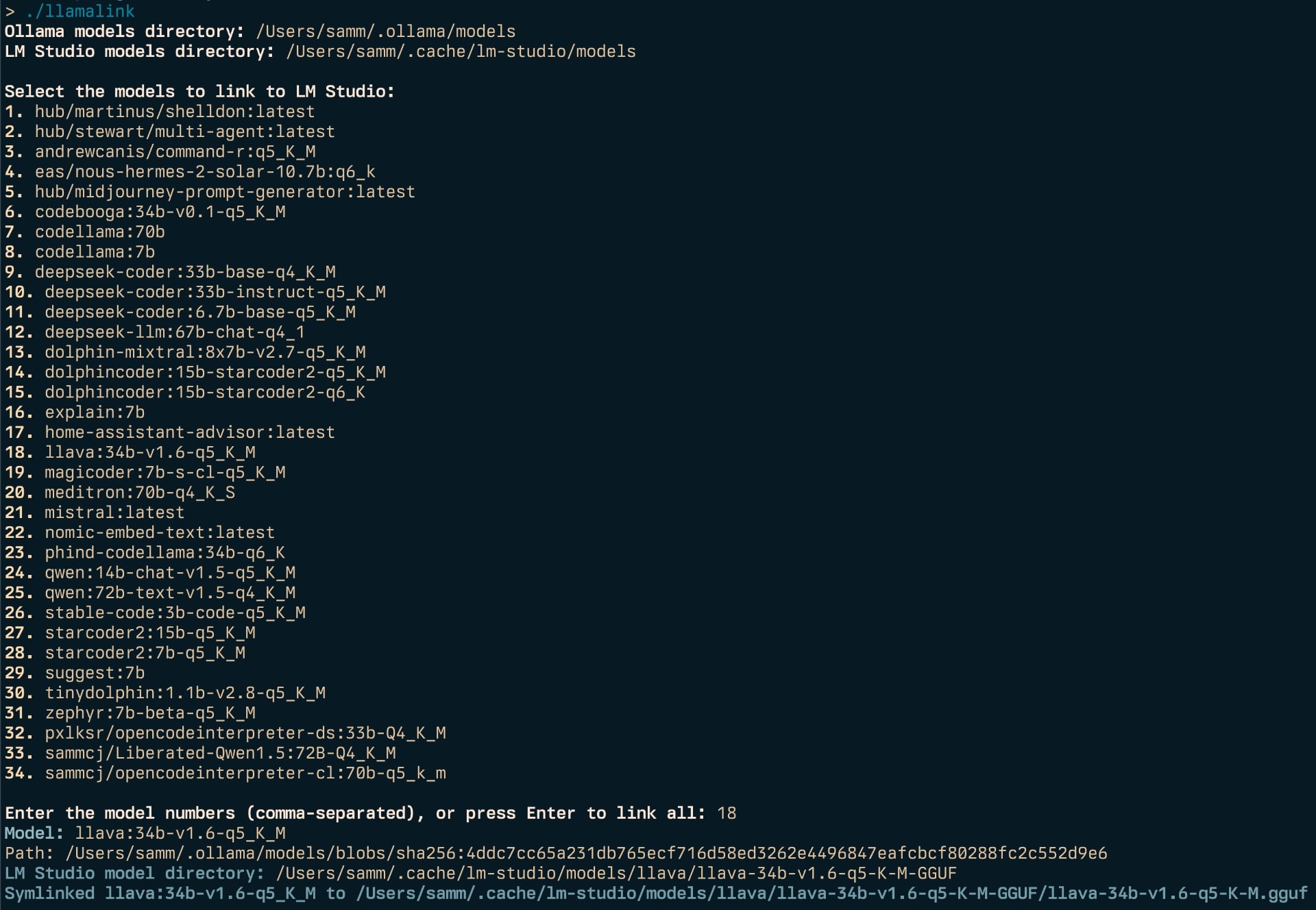
Llamalink - Ollama to LM Studio LLM Model Linker
Two of my most commonly used LLM tools are Ollama and LM Studio. Unfortunately they store their models in different locations and filenames. Manually copying or linking files was a pain, so I wrote a simple command-line tool to automate the process. This is why I created Llamalink. Ollama is a cross-platform model server that allows you to run LLMs and manage their models in a similar way to Docker containers and images, while LM Studio is a macOS app that provides a user-friendly interface for running LLMs. ...