Large Language Models don’t generate text deterministically - they use probabilistic sampling to select the next token based on prediction probabilities. How these probabilities are filtered and adjusted before sampling significantly impacts output quality.
This guide explains the key sampling parameters, how they interact, and provides recommended settings for different use cases.
Framework Reference
Last updated: November 2025
Parameter Comparison
| Parameter | llama.cpp | Default | Ollama | Default | MLX |
|---|---|---|---|---|---|
| Temperature | temp | 0.8 | temperature | 0.8 | temp |
| Top P | top_p | 0.9 | top_p | 0.9 | top_p |
| Min P | min_p | 0.1 | min_p | 0.0 | min_p |
| Top K | top_k | 40 | top_k | 40 | top_k |
| Repeat Penalty | repeat_penalty | 1.0 | repeat_penalty | 1.1 | Unsupported |
| Repeat Last N | repeat_last_n | 64 | repeat_last_n | 64 | Unsupported |
| Presence Penalty | presence_penalty | 0.0 | presence_penalty | - | Unsupported |
| Frequency Penalty | frequency_penalty | 0.0 | frequency_penalty | - | Unsupported |
| Mirostat | mirostat | 0 | mirostat | 0 | Unsupported |
| Mirostat Tau | mirostat_ent | 5.0 | mirostat_tau | 5.0 | Unsupported |
| Mirostat Eta | mirostat_lr | 0.1 | mirostat_eta | 0.1 | Unsupported |
| Top N Sigma | top_nsigma | -1.0 | Unsupported | - | Unsupported |
| Typical P | typical_p | 1.0 | typical_p | 1.0 | Unsupported |
| XTC Probability | xtc_probability | 0.0 | Unsupported | - | xtc_probability |
| XTC Threshold | xtc_threshold | 0.1 | Unsupported | - | xtc_threshold |
| DRY Multiplier | dry_multiplier | 0.0 | Unsupported | - | Unsupported |
| DRY Base | dry_base | 1.75 | Unsupported | - | Unsupported |
| Dynamic Temp | dynatemp_range | 0.0 | Unsupported | - | Unsupported |
| Seed | seed | -1 | seed | 0 | - |
| Context Size | ctx_size | 2048 | num_ctx | 2048 | - |
| Max Tokens | n_predict | -1 | num_predict | -1 | - |
Notable Default Differences
| Parameter | llama.cpp | Ollama | Note |
|---|---|---|---|
| min_p | 0.1 | 0.0 | Ollama disables Min P by default |
| repeat_penalty | 1.0 | 1.1 | Ollama applies penalty by default |
| seed | -1 (random) | 0 | Different random behaviour |
Feature Support
| Feature | llama.cpp | Ollama | MLX |
|---|---|---|---|
| Core (temp, top_p, top_k, min_p) | ✓ | ✓ | ✓ |
| Repetition penalties | ✓ | ✓ | ✗ |
| Presence/frequency penalties | ✓ | ✓ | ✗ |
| Mirostat | ✓ | ✓ | ✗ |
| Advanced (DRY, XTC, typical, dynatemp) | ✓ | ✗ | Partial |
| Custom sampler ordering | ✓ | ✗ | ✗ |
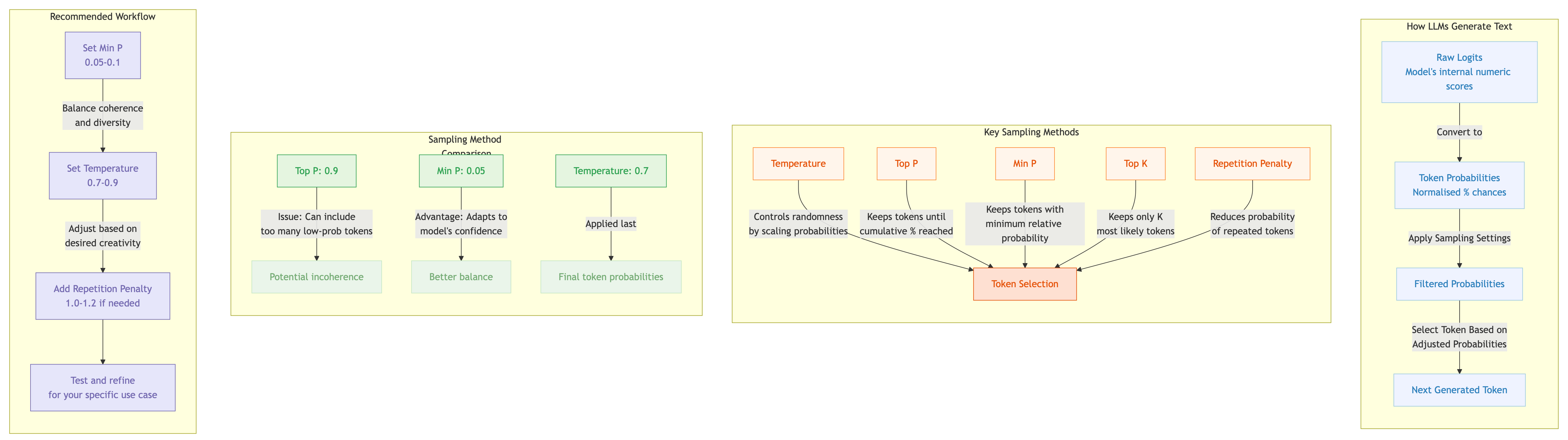
Core Sampling Parameters
Temperature
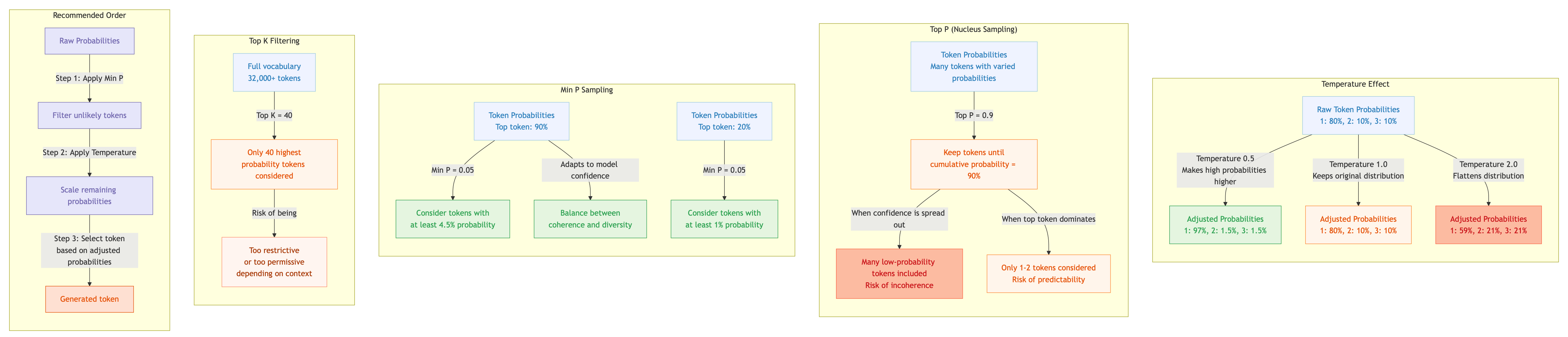
Controls the randomness of token selection by modifying the probability distribution before sampling.
The formula: Each token’s logit (raw score) is divided by the temperature value, then softmax produces final probabilities:
adjusted_probability = softmax(logits / temperature)
Values explained:
- 1.0 (baseline): The model’s original probability distribution is used as-is. This is the baseline, not “disabled”. If the model assigns “the” a 40% probability and “a” a 30% probability, those exact values are used for sampling.
- < 1.0 (e.g., 0.5): Makes the distribution sharper. High-probability tokens become more likely, low-probability tokens become less likely. Output becomes more deterministic, favouring the model’s top choices.
- > 1.0 (e.g., 2.0): Makes the distribution flatter. Probabilities become more uniform, giving lower-ranked tokens a better chance. Output becomes more random and varied.
- 0: Greedy decoding. Always selects the highest probability token. Fully deterministic. (Implementations handle this as argmax rather than literal division by zero.)
- → ∞: Approaches uniform random selection across all tokens.
Example: Say the model’s top 3 tokens have these base probabilities (at temp 1.0):
- “cat”: 60%
- “dog”: 30%
- “fish”: 10%
At temp 0.5: Distribution sharpens - “cat” dominates even more strongly (~85%), others become unlikely.
At temp 2.0: Distribution flattens - probabilities converge toward each other (~40%, ~35%, ~25%).
(Exact values depend on the underlying logits; these illustrate the directional effect.)
Key points:
- Temperature changes have more impact at lower values (0.5→0.6 is more significant than 1.5→1.6)
- Temperature is often used alongside top-p and top-k, which truncate the distribution before sampling. Temperature reshapes probabilities; top-p/top-k restrict which tokens are considered at all.
- Applied after filtering methods in the standard pipeline
- Lower temperatures suit factual, deterministic tasks. Higher temperatures suit creative work where variety is desirable.
What is a logit?
A logit is the raw, unnormalised output value from a model before being transformed through softmax to produce probabilities. The term comes from logistic regression where it refers to log-odds.
Top P (Nucleus Sampling)
Restricts token selection to the smallest set whose cumulative probability exceeds threshold P.
How it works: Tokens are sorted by probability and summed until reaching the threshold (e.g., 0.9 for 90%). Only tokens in this “nucleus” are considered.
Strengths: Guarantees sampled tokens come from a set representing a fixed proportion of total probability mass.
Limitations:
- With flat distributions (low confidence), may include many low-probability tokens
- With peaked distributions (high confidence), may select only one or two tokens
- Doesn’t adapt candidate set size based on model confidence
Recommended values: 0.9 for general use, 0.8 for factual, 0.95 for creative. Set to 1.0 to disable.
Min P
Filters vocabulary to include only tokens whose probability is at least a fraction of the most likely token’s probability.
How it works: Calculate threshold as min_p × probability_of_top_token. Only tokens above this threshold are considered.
Key advantage - adaptability:
- High confidence (top token has high probability) → higher threshold → smaller, focused candidate set
- Low confidence (probabilities spread out) → lower threshold → more diverse candidates
This avoids including too many unlikely tokens (unlike Top P in flat distributions) while preserving alternatives when one token dominates.
Sensitivity:
- Very low (0.01): Little filtering when distributions are flat
- Very high (0.2+): Can become overly restrictive
Recommended values: 0.05-0.1 provides good balance. Applied before temperature in the standard pipeline.
Top K
Restricts selection to the K highest-probability tokens, regardless of their actual values.
How it works: If top_k=40, only the 40 highest-probability tokens are considered.
Limitation: As a fixed-count filter, it can’t adapt to model confidence - too restrictive when many good alternatives exist, too permissive when only a few tokens are meaningful.
Interaction with other filters: In llama.cpp, Top K applies first, creating an initial pool that subsequent filters (Top P, Min P) operate within.
Recommendation: For most use cases, disable (set to 0) and rely on Min P or Top P. Some models have specific recommendations (e.g., Gemma 3 recommends top_k=64).
Repeat Penalty
Discourages repeating tokens that appeared within the repeat_last_n window.
How it works: Applies a multiplicative penalty to logits of recently-seen tokens. Values > 1.0 decrease probability of recent tokens.
Cautions:
- Penalises any repetition, including necessary repetition (code syntax, key terms)
- Can produce awkward phrasing as the model avoids natural repetition
- Often masks underlying prompt or parameter issues
Related parameter - repeat_last_n: How far back to look. Use 64 for prose, 128-512 for code to capture variable names.
Recommendation: Start with 1.0 (disabled) or 1.05, increase only if problematic repetition persists. Never exceed 1.2.
Presence Penalty
Applies a fixed penalty to any token that has appeared at least once in the preceding context (prompt + generation).
Use case: Encourages introducing new concepts or tokens; discourages topic looping.
Difference from repeat_penalty: Presence penalty considers the entire context, not just a recent window, and applies the same penalty regardless of how many times a token appeared.
Recommended values: 0.0-0.5. Start at 0.0 (disabled).
Frequency Penalty
Penalises tokens based on how frequently they’ve appeared in the preceding context.
Use case: Reduces stylistic repetition and overuse of common words; increases lexical diversity.
Difference from presence_penalty: Frequency penalty scales with occurrence count - a word used 10 times gets penalised more than one used twice.
Recommended values: 0.0-0.5. Start at 0.0 (disabled).
Advanced Parameters
Mirostat
An adaptive sampling method that dynamically adjusts constraints to maintain a target level of “surprise” (perplexity).
Modes:
- 0: Disabled
- 1: Mirostat (original)
- 2: Mirostat 2.0 (generally preferred)
Parameters:
mirostat_tau(target entropy): Lower (2.0-3.0) = more focused, higher (4.0-6.0) = more diversemirostat_eta(learning rate): How quickly it adjusts. Default 0.1.
Usage: When enabling Mirostat, disable other filters by setting top_p=1.0, top_k=0, min_p=0.0. It acts as an alternative sampling controller.
When to use:
- Long-form text where consistent quality matters
- When you prefer adaptive control over manual tuning
- To prevent quality degradation over extended generations
Starting values: mirostat=2, mirostat_tau=5.0, mirostat_eta=0.1
Other Sampling Methods
| Parameter | Name | Description | Use Case | Range |
|---|---|---|---|---|
tfs_z | Tail Free Sampling | Filters low-probability tail based on second derivative | Alternative to Top P/Min P | 0.9-1.0 (1.0 disables) |
typical_p | Typical Sampling | Selects tokens close to expected probability | Surprising yet coherent outputs | 0.9-1.0 (1.0 disables) |
top_a | Top-A | Threshold based on squared top probability | Adaptive filtering | 0.0-1.0 (0.0 disables) |
dry_* | DRY | Detects and penalises repeating n-gram patterns | Prevents phrase recycling | Multiplier 0.0-2.0 |
dynatemp_* | Dynamic Temperature | Adjusts temp based on distribution entropy | Automatic temperature tuning | Range 0.0-2.0 |
top_n_sigma | Top-N-Sigma | Threshold at max logit minus N standard deviations | Statistical filtering | 1.0-3.0 (-1.0 disables) |
xtc_* | XTC | Occasionally forces lower-probability token selection | Breaks predictable patterns | Prob 0.0-1.0, Thresh 0.1 |
Sampler Ordering
The order in which sampling methods apply significantly impacts output. The default llama.cpp pipeline:
penalties → dry → top_n_sigma → top_k → typ_p → top_p → min_p → xtc → temperature
Why this order matters:
- Penalties modify initial logits
- Filters remove low-probability or undesirable tokens based on original predictions
- Temperature rescales logits of remaining candidates
- Softmax converts to probabilities, then sampling occurs
Applying temperature before filtering could distort the distribution, causing unwanted tokens to pass filters or good tokens to be filtered out.
When using Mirostat, it replaces the filtering steps and dynamically controls the process itself.
llama.cpp Default Sampler Order
penalties → dry → top_n_sigma → top_k → typ_p → top_p → min_p → xtc → temperature
Shorthand sequence: edskypmxt
Customise with --samplers or --sampling-seq.
Diagrams
Troubleshooting
Before adjusting parameters, check:
- Prompt quality: Is it clear and specific?
- Context window: Has the limit been reached?
- Model suitability: Is the model appropriate for the task?
Model keeps repeating itself
Note: Perform changes one at a time to isolate effects.
- Check prompt doesn’t encourage repetition
- Gradually increase
repeat_penalty(start with 1.05, max 1.15-1.2~) - Try
frequency_penalty(0.1-0.5) orpresence_penalty(0.1-0.5) - Slightly increase
min_por decreasetop_p
Outputs too random/incoherent
- Lower temperature (try 0.6, then 0.4)
- Increase
min_pto 0.1 - If still problematic, enable
top_k=40
Outputs too generic/predictable
- Increase temperature (0.7-1.0)
- Lower
min_pto 0.03-0.05 - Ensure
top_kis disabled (0)
Model generates incorrect facts
- Lower temperature significantly (0.3 or 0.1)
- Increase
min_pto 0.1-0.15 - Adjust prompting to encourage factual accuracy
Appendix: Code Generation Parameters
Code generation has unique requirements - intentional repetition (variable names, syntax patterns) combined with precision needs.
Key Considerations
- Repetition handling: Low or no repeat penalties (1.0-1.05) work better than for text
- Context length: Longer repeat lookback (128-512) maintains variable naming consistency
- Temperature sweet spot: 0.1-0.7 for most code tasks
- Precision vs. creativity: Lower (0.1-0.2) for critical implementations, slightly higher (0.3-0.6) when multiple valid approaches exist