Over the last two months I’ve been running selected IO intensive servers off the the SSD storage cluster, these hosts include (among others) our:
- Primary Puppetmaster
- Gitlab server
- Redmine app and database servers
- Nagios servers
- Several Docker database host servers
Reliability
We haven’t had any software or hardware failures since commissioning the storage units.
During this time we have had 3 disk failures on our HP StoreVirtual SANs that have required us to call the supporting vendor and replace failed disks.
We have performed a great deal of live cluster failovers without any noticeable interruption to services and with no unexpected results.
Expected findings
Significantly higher disk and CPU throughput when required
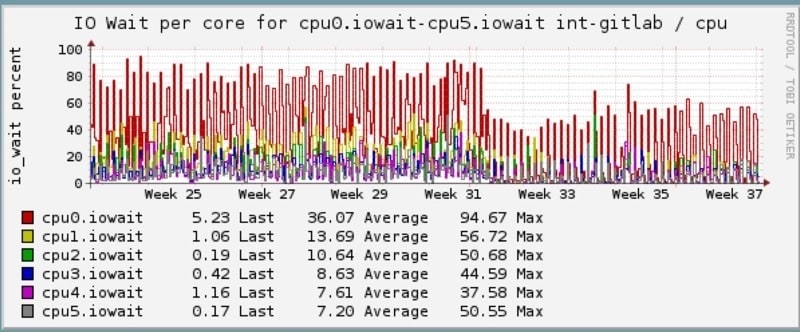
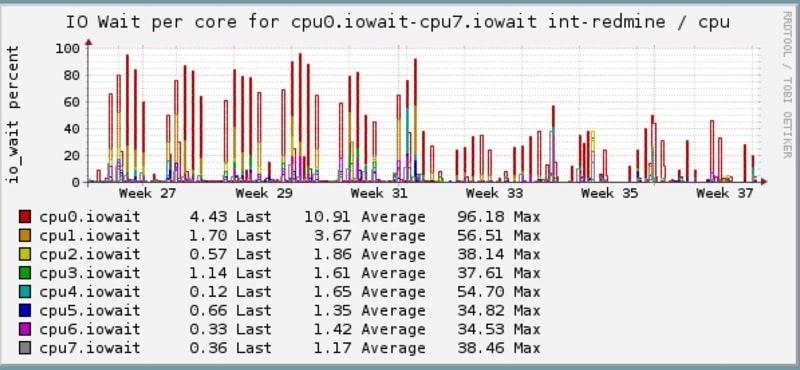
IOWait on VMs greatly reduced
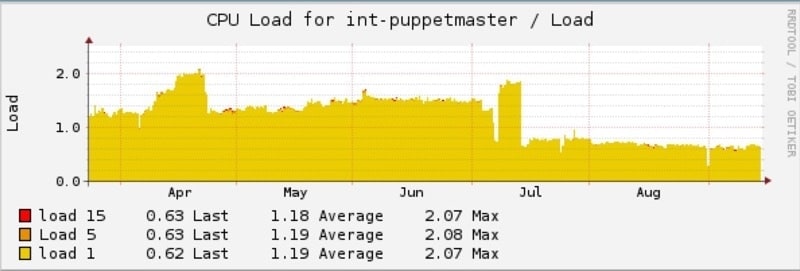
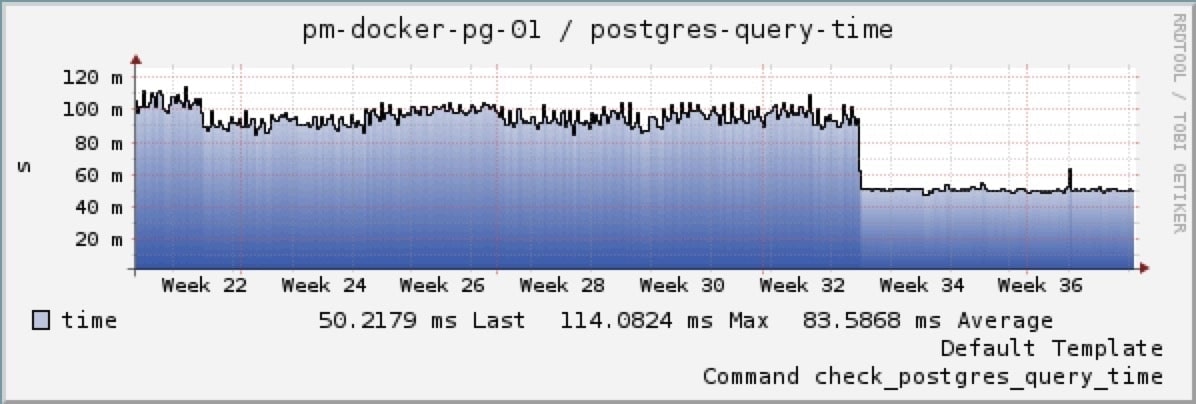
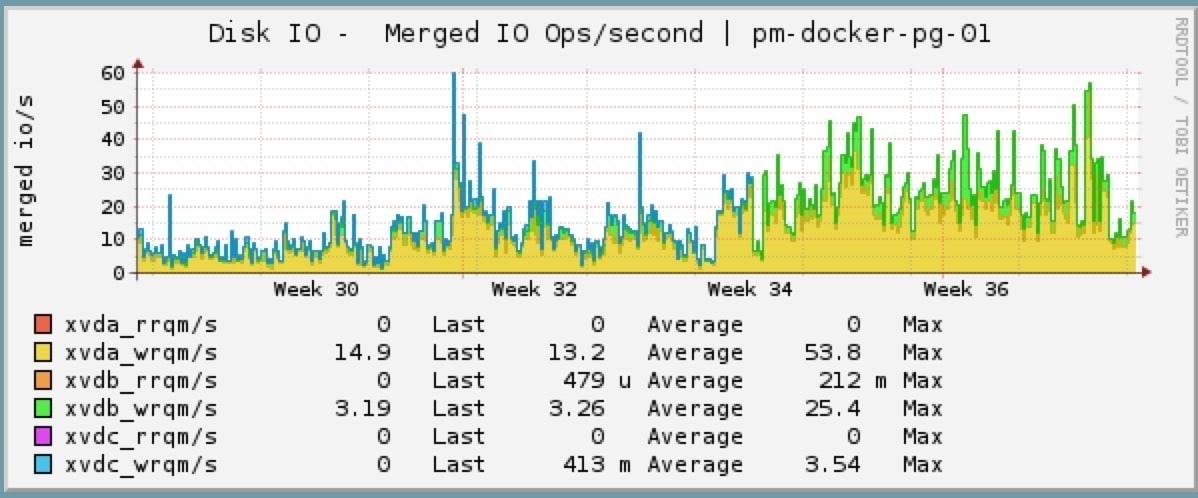
VM IO latency has been reduced 300-500%
Before:
4096 bytes from . (ext4 /dev/mapper/debian-root): request=1 time=1.6 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=2 time=4.7 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=3 time=3.7 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=4 time=4.7 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=5 time=4.8 ms
After:
4096 bytes from . (ext4 /dev/mapper/debian-root): request=1 time=0.5 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=2 time=0.7 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=3 time=0.9 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=4 time=0.7 ms
4096 bytes from . (ext4 /dev/mapper/debian-root): request=5 time=0.6 ms
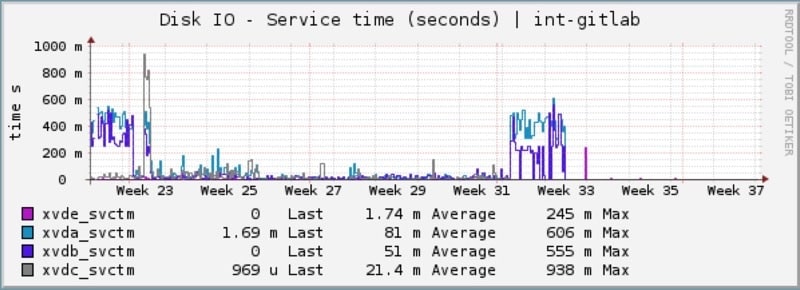
Increased reliability of performance data
Previously many hosts that we were monitoring load related statistics on previous had broken PNP4Nagios graphs as they were so starved for disk IO that checks would time out or fail to reliably return performance information, this has been resolved on the new storage.
Unexpected findings
Decreased network latency
On hosts we’ve moved to the new storage we’ve noticed a significant decrease in ping latency to these hosts. I haven’t investigated this but it’s not something I was expecting to see.
Increased SSH / login performance
I didn’t think this would be very noticeable but it’s become blatantly obvious when you’re sshing into a server running on the new storage. While this is a ’nice to have’ from an admin perspective - it makes a huge difference to remote automation such as puppet runs etc… This likely a combination of the time it takes to write the logs and the decreased network latency mentioned above.