smcleod.net 👋
The personal blog of Sam McLeod. I write about AI, DevOps, Platform Engineering, and other geeky topics.
I write and review a lot of Agent Skills, and find myself frequently pushing back in reviews, as many authors assume they’re writing “just another markdown prompt” without considering that they’re actually working with one component of an agentic system. The TLDR of my feedback is usually along the lines of: The description’s only job is to tell the agent when the skill should be triggered. Keep the description as terse as possible while still triggering. The SKILL.md should be lean with detail pushed to reference files. Put repeatable work in scripts rather than relying on model inference. Skill Creator Primer I recommend teams use or create their own version of my skill-creator-primer skill. ...
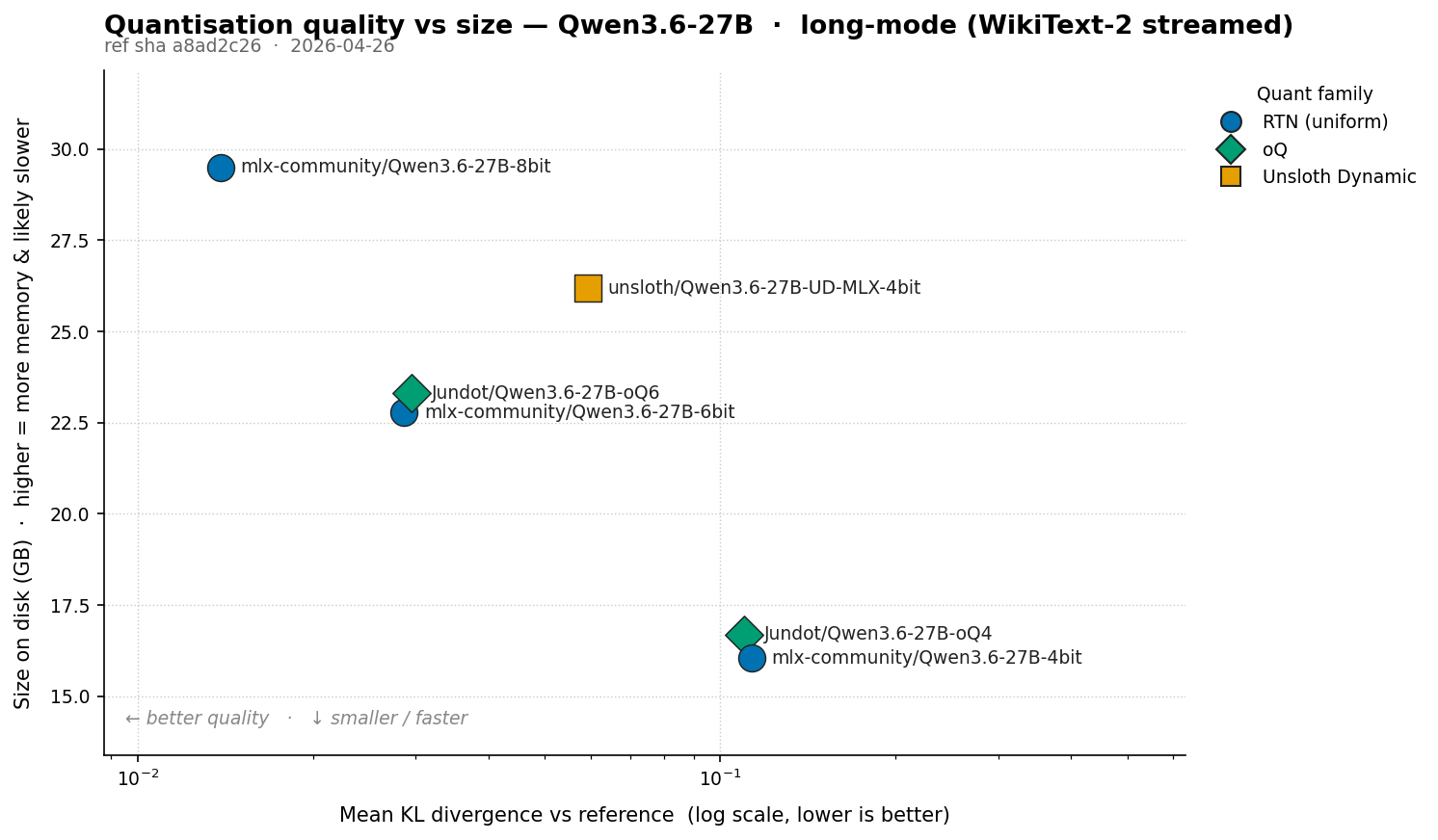
KL divergence against a known-good reference answers “how much did this quant change the model’s behaviour?” rather than “how good is this model overall?”. What KLD measures KL divergence measures how much one probability distribution disagrees with another. At each token position, both the reference and the quantised model emit a distribution over the full vocabulary (~248k tokens for Qwen-class models). The reference might say "~80% likely the, ~5% likely a, …"; the quant says something slightly different. KLD compares the two per position and averages. ...
Starting with the M4 and including the new M5 generations of Apple Silicon, macOS no longer offers or allows full-resolution HiDPI 4k modes for external displays. The maximum HiDPI mode available on a 3840x2160 panel is now just 3360x1890 - M2/M3 machines did not have this limitation. With this regression Apple is leaving users to choose between: Full screen real estate at 4k (3840x2160) with blurry text due to HiDPI being disabled. or ...
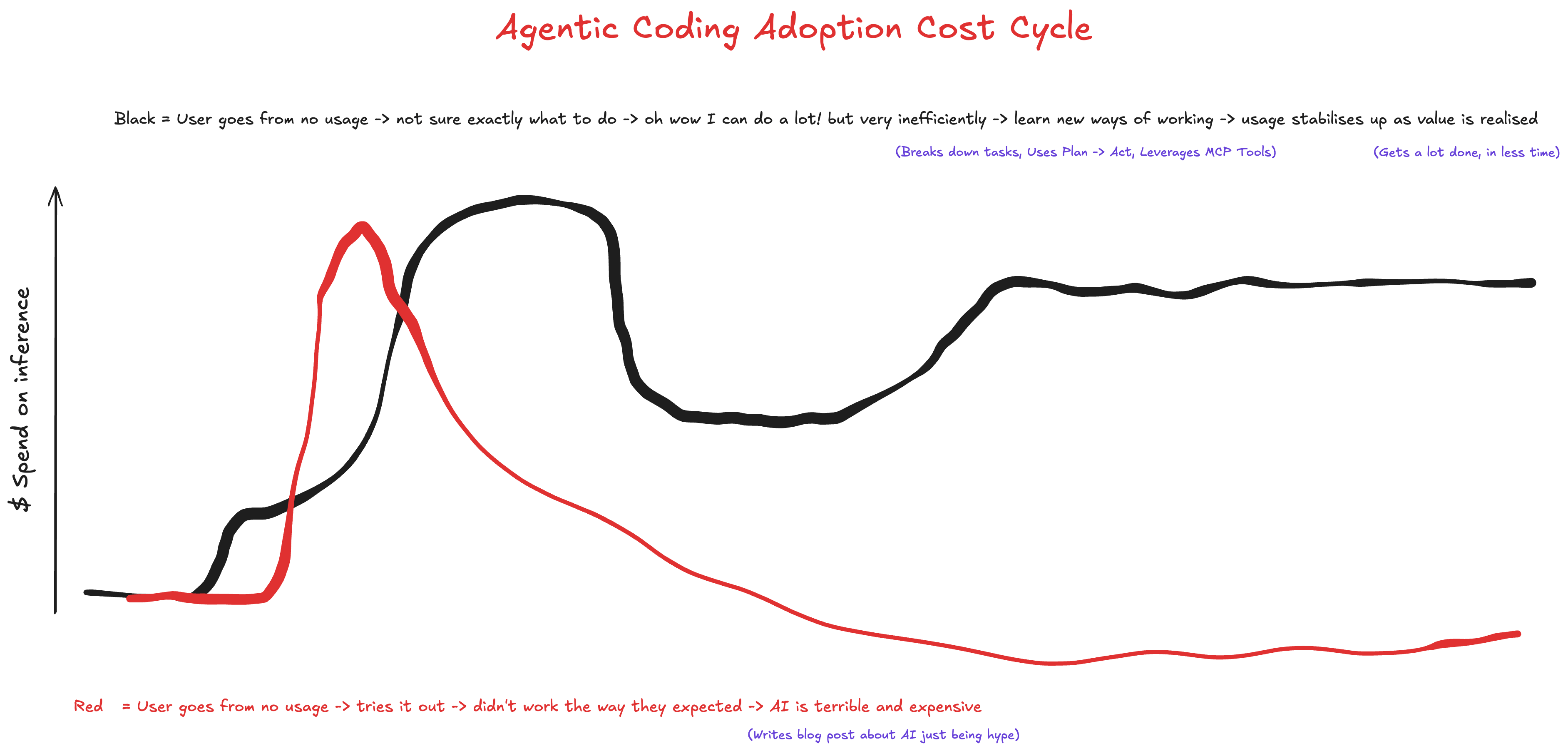
Configuration Agent rules - concise, scoped CLAUDE.md files that shape agent behaviour Sandboxing - constrain file access and network connections Permissions - pre-approve safe operations, hard-block dangerous ones Hooks - run shell commands before/after tool calls as a safety net Extend knowledge and capabilities Skills - dynamic knowledge acquisition with progressive disclosure Language servers - give the agent go-to-definition, find-references, and type checking MCP tools - external tool servers, used sparingly Workflow Plan before acting - read-only exploration and task definition Embrace starting fresh sessions - keep context clean Template out common commands - reusable prompts for common tasks ...
NVIDIA artificially restricts peer-to-peer (P2P) GPU communication to their enterprise cards. Turns out this is a software limitation, not a hardware one. I patched my drivers to remove it, hacked vLLM to take advantage of it, and got a 15-50% throughput improvement running Qwen 3.5 35b on dual RTX 3090s.
An observation on functional correctness without domain quality.
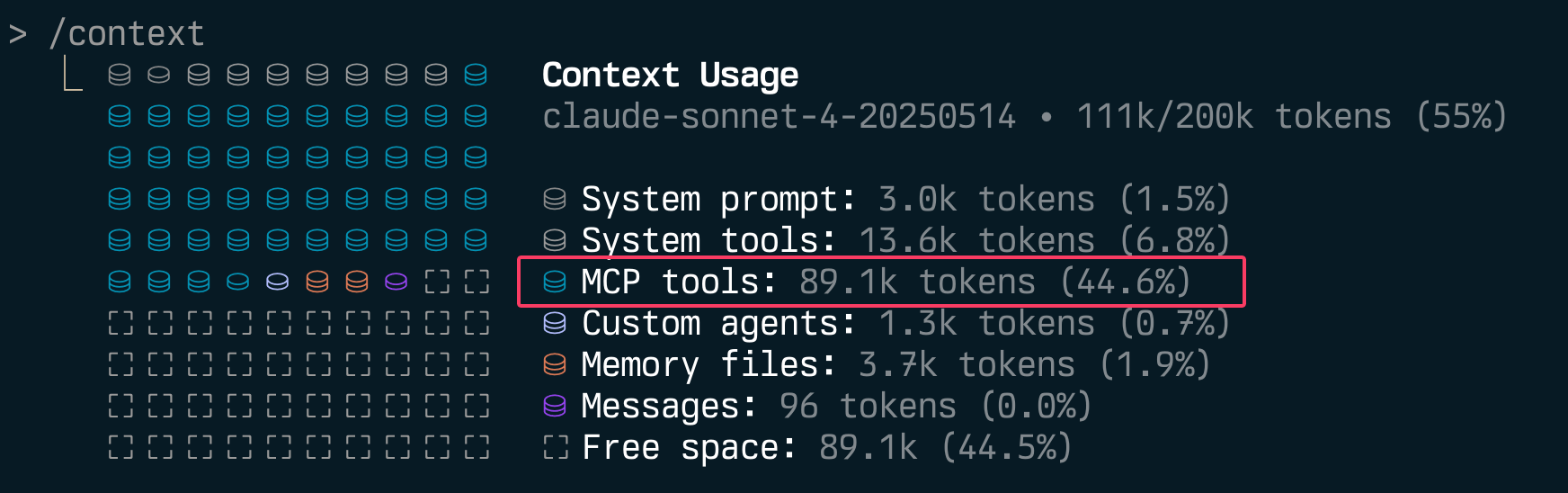
If you’re building MCP servers, you should be adding the ability to disable individual tools.
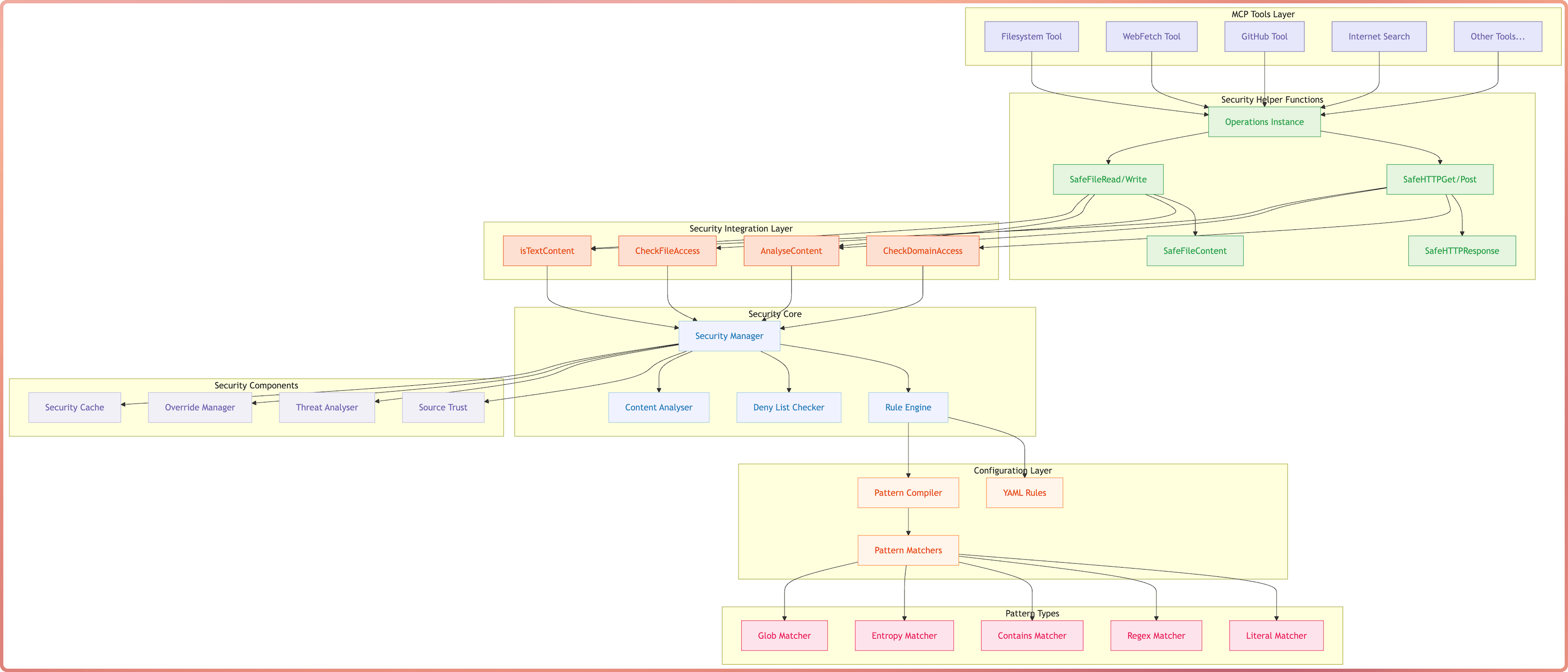
MCP DevTools - The one tool that replaced the 10-15 odd NodeJS/Python/Rust MCP servers I had running at any given to for agentic coding tools with a single server that provides tools I consider useful for agents when coding. The Problem The MCP ecosystem has grown rapidly, but I found myself managing many separate servers, each often running multiple times for every MCP client I had running, not to mention the ever growing memory and CPU consumption of the many NodeJS or Python processes. ...
Square Peg hosted event on June 20, 2025 where I demonstrated a basic version of my daily Agentic Coding workflow using Cline and MCP tools. What does it take to write enterprise-grade code in the AI-native era? Join Square Peg investors James Tynan and Grace Dalla-Bona for a live demo and Q&A session with three leading AI-native developers - Grant Gurvis, Listiarso Wastuargo, and Sam McLeod - and get a behind-the-curtain look at the workflows that enable them to ship faster, smarter, and cleaner code using tools like Cursor, Cline, and smolagents. ...